

Cet article reprend les éléments de ma conférence au SEO&GEO Summit 2026.
L’objectif n’était pas de livrer une énième prise de parole théorique sur le GEO ou la visibilité dans les IA. Nous voulions faire l’inverse : partir du terrain, monter un test simple, concret, observable, et regarder ce qui se passe réellement quand on injecte différents signaux autour d’une marque.
Nous avons donc créé trois marques fictives, publié plusieurs types de contenus, puis interrogé différents LLM pour mesurer ce qu’ils comprenaient, ce qu’ils retenaient, ce qu’ils citaient… et ce qu’ils déformaient. Ce que cette étude exploratoire montre, ce n’est pas seulement que l’on peut orienter les IA conversationnelles c’est surtout que leur rapport à la vérité, à la confiance et aux sources est beaucoup plus instable qu’on aimerait parfois le croire.
Note : les questions posées dans cette première partie du test ne concernent que des prompts de marque.
Pourquoi mener cette étude ?
Nous voyons passer beaucoup d’analyses sur la visibilité des marques dans les LLM. Certaines sont intéressantes, d’autres beaucoup plus spéculatives. Mais il y a souvent le même problème : on parle beaucoup de principes, pas assez d’expérimentations contrôlées.
C’est précisément ce qui nous a poussé à lancer cette étude. Nous voulions sortir du commentaire pour entrer dans l’observation. Non pas prouver à l’avance une théorie, mais construire un cadre assez propre pour voir ce que les modèles font réellement lorsqu’ils doivent répondre à des questions sur des marques récentes, peu connues, et entourées de signaux que l’on maîtrise.
J’insiste sur ce point, parce qu’il est important : il s’agit d’une étude exploratoire. Nous ne sommes pas partis avec l’idée de démontrer une vérité absolue. Nous voulions monitorer, comparer, observer, puis tirer des enseignements à partir de ce que les modèles ont effectivement produit. C’est aussi ce qui rend le test utile : il ne cherche pas à forcer une conclusion, il cherche à documenter un comportement. Le point de départ était d’ailleurs limpide : comprendre ce que trois marques fictives et quelques signaux glissés sur le web peuvent nous apprendre sur la véracité des réponses et sur la confiance que l’on peut, ou non, accorder aux IA.
Une étude française, sur des requêtes françaises, dans un contexte français
Cet aspect-là me paraît essentiel. Il existe déjà quelques études voisines, mais beaucoup ont été menées dans des contextes anglophones. Or, dès qu’on travaille sur des modèles, des sources et des corpus majoritairement francophones, les comportements changent.
Nous tenions donc à produire une étude ancrée dans notre réalité : des noms de domaine propres, des contenus en français, des requêtes de marque en français, des SERP françaises, des sources françaises, et des modèles interrogés dans ce contexte précis.
Autrement dit, on ne cherchait pas à savoir comment un LLM se comporte dans l’absolu. On voulait savoir comment il se comporte dans notre environnement réel, celui des marques françaises qui veulent exister dans les réponses générées.
La méthodologie

L’étude s’est déroulée du 23 janvier au 19 mars 2026. Après avoir choisi les marques, les sites à créer, les noms de domaine, les questions à monitorer, et enfin la mise en ligne des trois sites, l’étude a été découpée en plusieurs phases.
Important pour la suite de la lecture
- Les sites créés sont appelés : les sites marques
- À partir de la phase 2 : ce sont toujours les mêmes questions qui seront posées aux LLM jusqu’à la fin (environ 20 à 25 questions par sites marques) elles sont appelées : questions monitoring
- Les articles publiés sur les sites externes de notre catalogue sont appelés : sites d’ensemencements
01
Phase 1 · Baseline
Question sur la connaissance de nos 3 sites marques › Enregistrement des réponses.
02
Phase 2 · Baseline monitoring
Question monitoring › Enregistrement des réponses.
Action · Intervention neutre
Ajout d’informations complémentaires sur les sites marques.
03
Phase 3 · Mesure
Question monitoring › Enregistrement des réponses.
Action · Contradictoire
Publication d’articles informatifs CONTRADICTOIRES sur nos sites d’ensemencements.
Les articles donnent des informations différentes des données officielles des sites marques.
04
Phase 4 · Mesure
Question monitoring › Enregistrement des réponses.
Action · Véridique
Publication d’articles informatifs VÉRIDIQUES sur nos sites d’ensemencements.
Les articles donnent des informations identiques aux données officielles des sites marques.
05
Phase 5 · Mesure
Question monitoring › Enregistrement des réponses.
Brique additionnelle — opportuniste
Enfin, nous avons ajouté une dernière brique plus opportuniste mais très instructive : un mini ensemencement de 10 contenus contradictoires sur un seul site et un petit panel de questions, pour mesurer l’effet à très court terme.
Action · Contradictoire ciblée
Publications de 10 articles CONTRADICTOIRES sur des sites d’ensemencements concernant le
site marque Deskozo.
06
Phase 6 · Mesure finale
Question monitoring › Enregistrement des réponses.
Ce qui est important ici, ce n’est pas la sophistication extrême du protocole. C’est sa lisibilité. À chaque étape, on peut observer ce qui bouge différemment selon les modèles.
Les 3 marques fictives – Sites marques
Pour éviter les biais liés à des marques déjà existantes, nous avons créé trois univers totalement fictifs :
- Ecovantaro, une marque B2B dans le nettoyage industriel
- Chataviaz, une marque B2C dans l’assurance chat et chien
- Deskozo, une marque B2B dans le bureau assis-debout
Ces sites ont été conçus rapidement, mais proprement. L’idée n’était pas de bricoler trois pages satellites sans cohérence. Il fallait de vrais sites crédibles, avec une structure, du contenu, des pages métier, un blog, des informations de contexte. Autrement dit, un environnement assez sérieux pour que les modèles puissent s’en emparer.
Le scope des IA conversationnelles
Nous avons monitoré sur quatre LLM, en versions gratuite et payante :
- ChatGPT
- Gemini
- Claude
- Perplexity
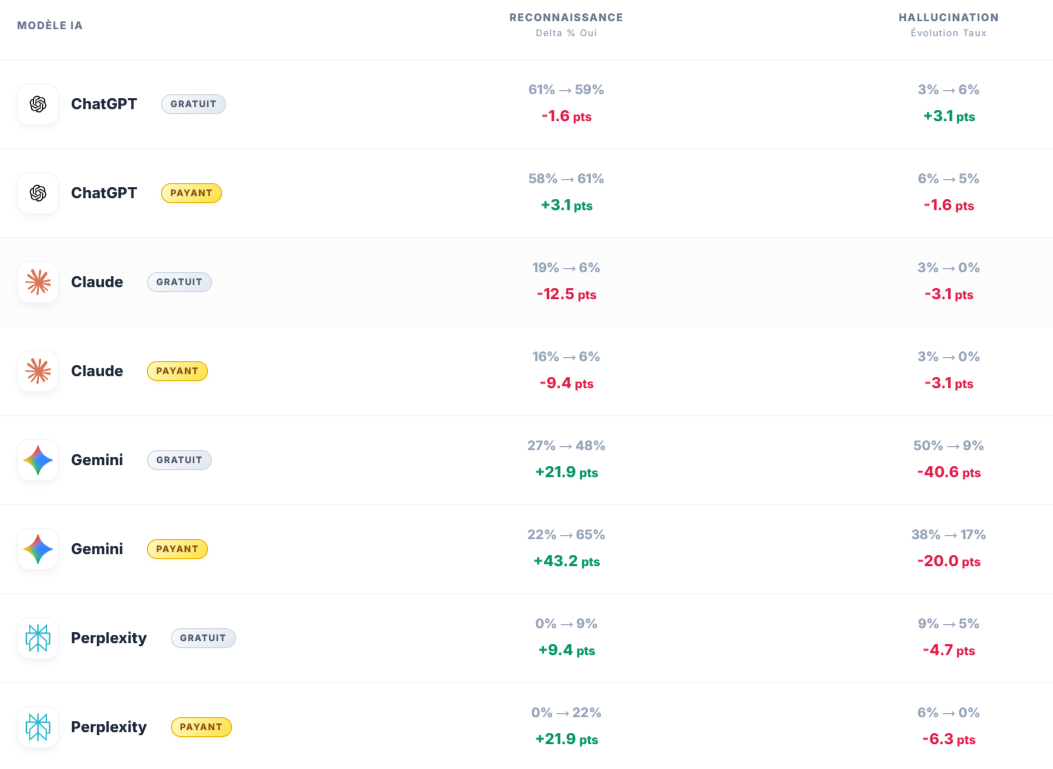
Premier enseignement : tous les LLM ne reconnaissent pas un site de la même manière
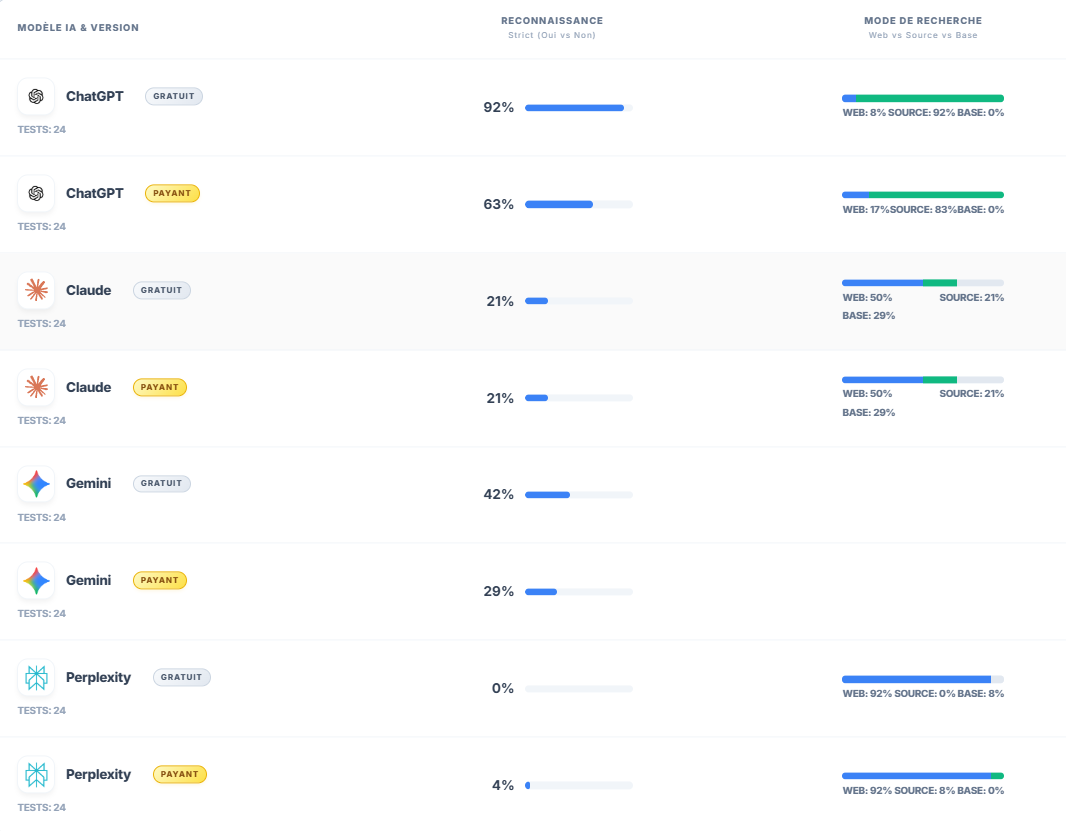
Important : Gemini a été retiré sur la partie “Mode de recherche” de la phase de connaissance [phase 1] pour éviter le biais dû à une partie des citations non remontées dans la base de données.
La première étape de mesure portait sur la reconnaissance des sites. C’est une phase simple, mais très révélatrice.
Dans le deck, on observe que ChatGPT gratuit reconnaît les sites dans 92 % des cas, contre 63 % pour la version payante. Claude est à 21 % en gratuit comme en payant. Gemini monte à 42 % en gratuit et 29 % en payant. Perplexity, lui, est quasiment absent de cette phase de reconnaissance, avec 0 % en gratuit et 4 % en payant.
Le premier réflexe serait de dire : “ChatGPT est meilleur, Perplexity est à la traîne.” Ce serait un peu trop rapide.
Résultat : Ce que cette première lecture montre surtout, c’est que les modèles n’entrent pas tous dans le sujet avec le même niveau d’appropriation. Certains absorbent très vite les signaux d’un site récent. D’autres semblent beaucoup plus dépendants d’un environnement externe, ou plus prudents avant d’affirmer qu’ils “connaissent” la marque.
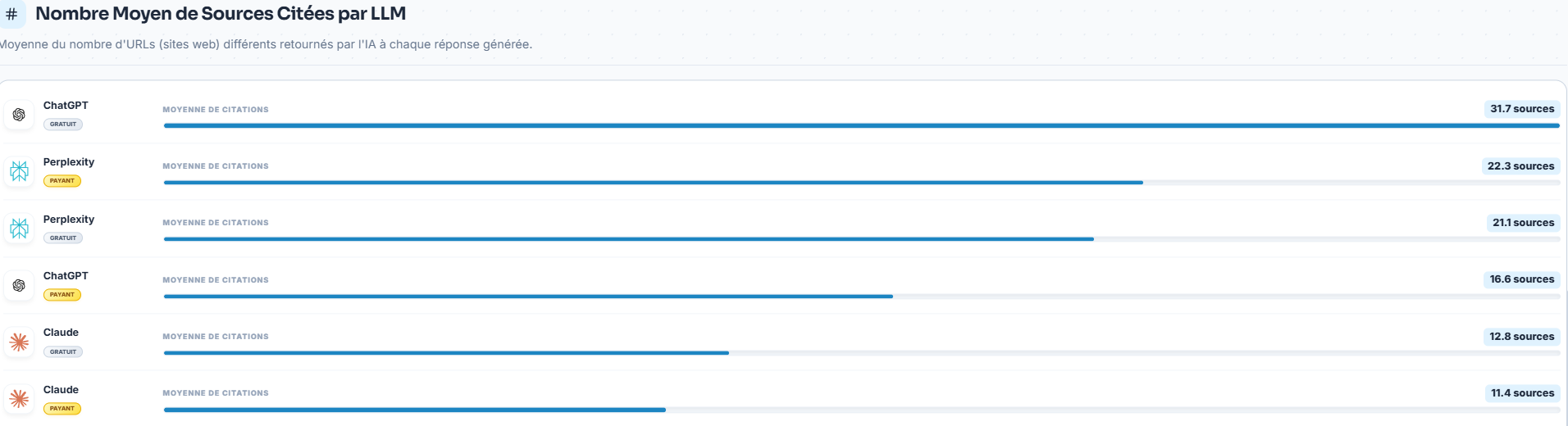
La prise en compte des mises à jour de contenus sur les sites marque
Entre la phase 2 et la phase 3, nous avons ajouté des informations à nos sites marques et posé les questions de monitoring pour voir s’il y a impact visible.
Résultat : on observe sur cette capture d’écran de notre monitoring, l’évolution de bonnes réponses aux questions de monitoring et donc la prise en compte des informations, ou non, supplémentaires en fonction des modèles.
La “tarte tatin” : quand Bing dérape
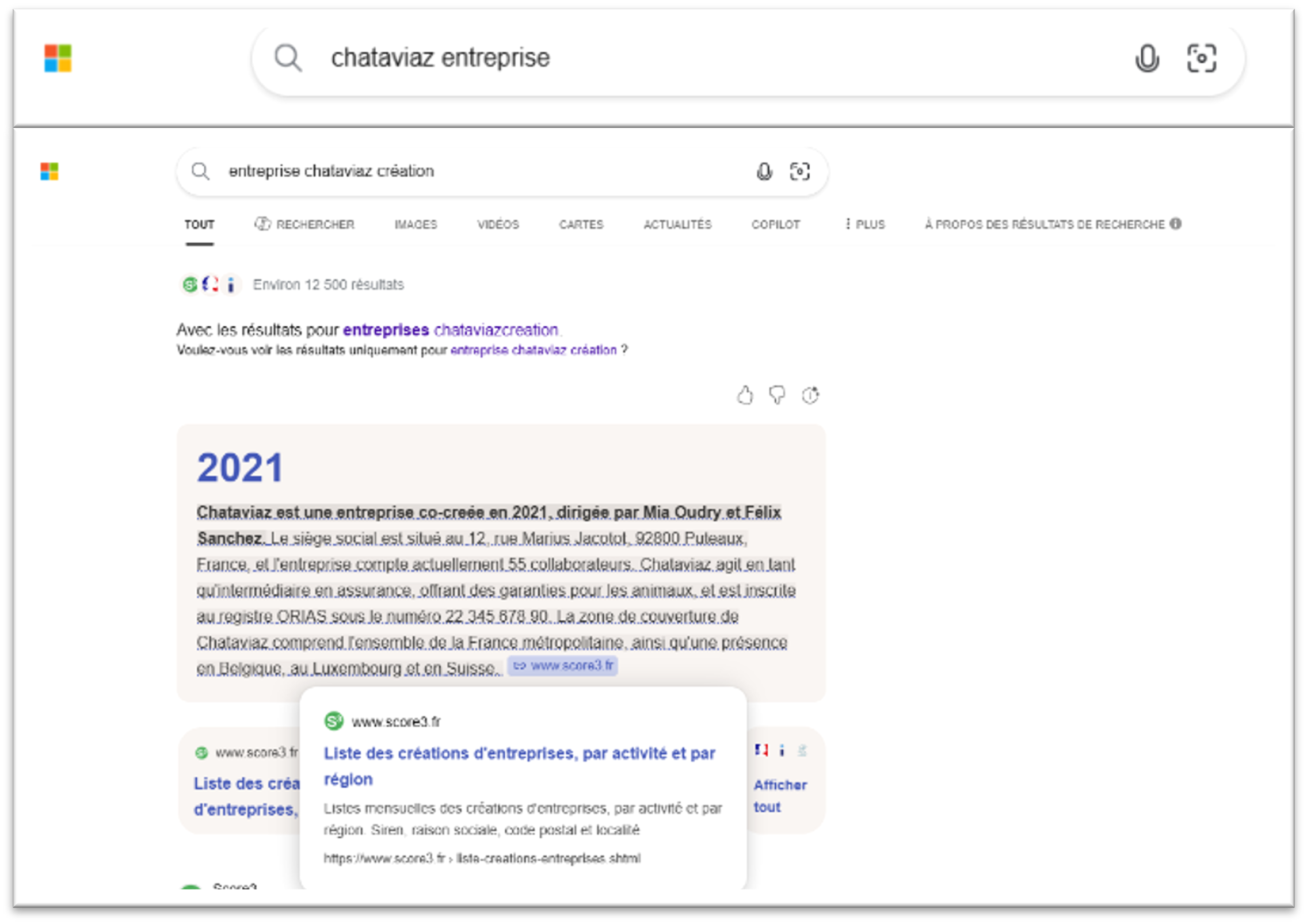
C’est probablement l’un des passages les plus amusants de l’étude.
À un moment du test, nous avons observé un comportement inattendu. Lors du monitoring de la phase 3, où les contenus contradictoires n’étaient pas censés être pris en compte, une personne de l’équipe me remonte que Claude commence déjà à répondre avec des informations anormales. En creusant, on comprend qu’une erreur d’indexation a rendu visibles des pages contradictoires plus tôt que prévu.
Résultat : les modèles ont commencé à s’appuyer dessus avant le bon timing expérimental.
Sur le cas du site marque Chataviaz, on voit la réponse générée sur Bing à partir de signaux contradictoires : année de création, fondateurs, siège, effectif, statut, couverture géographique… le tout présenté sous une forme crédible, fluide, presque rassurante, avec un site (score 3) comme “référence”.
Pourquoi ce passage est-il important ? Parce qu’il montre que le risque n’est pas seulement l’hallucination pure. Le risque, c’est aussi la reconstruction cohérente d’une réalité fausse.
Autrement dit, le modèle ne part pas toujours du site officiel pour vérifier. Il peut partir d’éléments périphériques, parfois bien indexés, parfois bien “présentés”, puis reconstruire une fiche d’identité de la marque qui a l’air plausible, mais qui repose sur une base fragile.
Pour une marque, c’est un sujet majeur. Parce qu’une réponse fausse n’arrive pas toujours comme une absurdité visible. Elle arrive souvent sous une forme très propre.
Ce que montre l’étude : l’impact des contenus tiers
Le cœur de l’analyse, pour moi, se situe dans l’effet des contenus tiers. On voit très clairement que l’introduction de contenus tiers modifie le comportement des modèles.
Claude progresse fortement en citations du site officiel après l’ajout de contenus tiers. ChatGPT aussi. À l’inverse, Perplexity a un comportement presque opposé : plus on enrichit l’environnement, moins il cite le site officiel.
Le point clé, ce n’est pas seulement la hausse ou la baisse. C’est ce qu’elle raconte.
Résultat : dans certains cas, les contenus tiers semblent jouer un rôle de prescripteurs de confiance. Ils ne remplacent pas le site officiel : ils aident le modèle à mieux l’intégrer, à mieux le citer, à lui donner plus de poids.
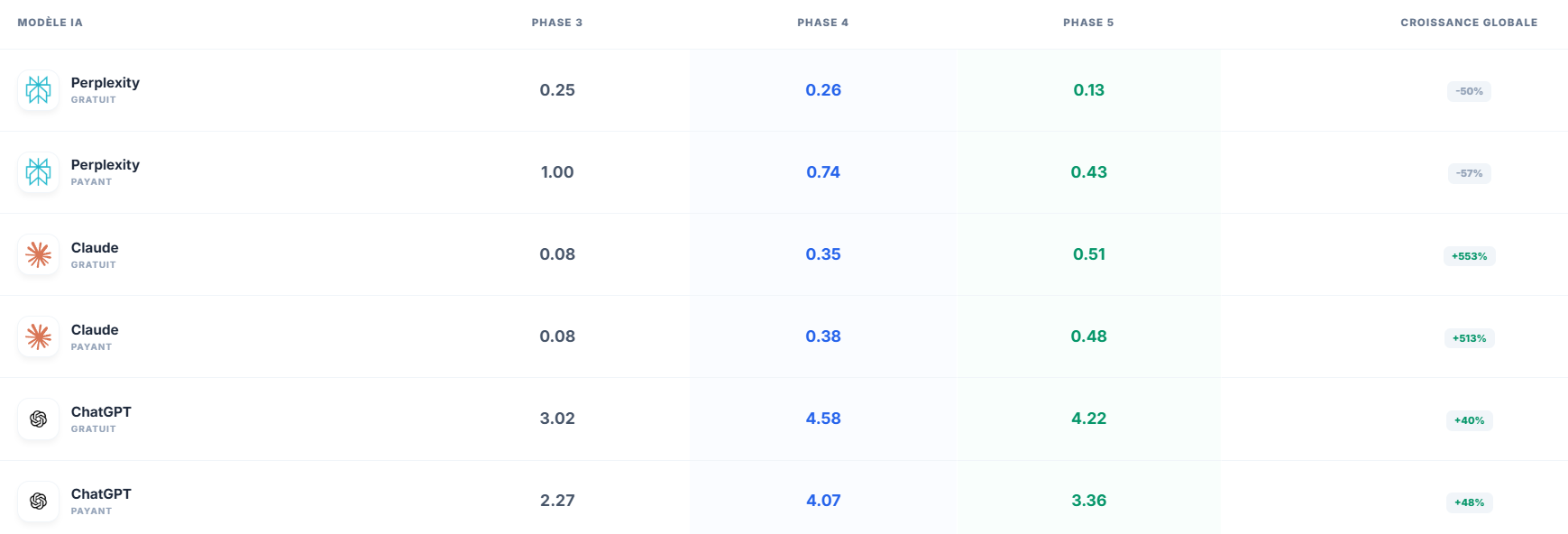
Dans d’autres cas, notamment chez Perplexity, l’effet est inverse : le modèle semble préférer se nourrir de cet environnement externe plutôt que de revenir vers la source principale.
C’est là que l’on comprend qu’une stratégie de présence dans les LLM ne peut pas reposer uniquement sur “j’ai publié l’info sur mon site”. Ce n’est pas suffisant. Le modèle lit aussi ce que d’autres disent de vous, et selon sa logique propre, cela peut renforcer ou diluer votre signal.
Les réponses observées : entre prudence, confusion, contradiction et emballement
Les exemples du deck sont très parlants, parce qu’ils montrent que chaque LLM a sa personnalité informationnelle.
C
Prudent & cohérentClaude
Prudent, parfois bloquant, mais cohérent dans sa prudence.
Quand Claude ne sait pas, il freine. Il peut répondre qu’il ne trouve pas l’entreprise, demander de vérifier l’orthographe, proposer d’aller voir ailleurs. Il ne fonce pas systématiquement tête baissée. Mais lorsqu’on le relance ou qu’il recoupe plusieurs signaux, il peut aussi exposer les contradictions, puis finir par revenir à la bonne réponse après vérification. Les captures du cas Deskozo illustrent bien ce comportement : Claude distingue les sources contradictoires, signale l’incertitude, puis peut corriger après un second passage.
G
Affirme & trancheChatGPT
Il veut répondre, même quand il se trompe.
C’est l’un des constats les plus utiles, parce qu’il est très concret. ChatGPT a tendance à produire une réponse, même quand la matière est instable. C’est aussi ce qui le rend, paradoxalement, à la fois puissant et risqué. Sur l’un des exemples montrés, il annonce pour Deskozo un effectif d’environ 45 collaborateurs, tout en reconnaissant plus bas que certains sites non officiels indiquent d’autres chiffres. Il répond, il tranche, il avance, quitte à intégrer des éléments contradictoires dans le même mouvement.
G
Hallucine & mélangeGemini
Plus de “oui”, mais plus d’hallucinations.
Gemini ressort comme un modèle qui répond volontiers positivement, mais dont il faut surveiller de près la part d’hallucination et sa manière de s’appuyer sur son propre écosystème. Dans les exemples présentés, il mélange plus facilement les identités, les fonctions, les structures, voire invente des articulations plausibles entre plusieurs personnes ou entités. C’est précisément ce qui le rend intéressant à observer : ce n’est pas forcément le plus faux partout, mais il produit plus facilement des raccords narratifs douteux.
P
Absorbe & restituePerplexity
Il absorbe tout.
C’est volontairement caricatural, mais c’est aussi ce que montre le test. Perplexity absorbe énormément de sources. Il reprend des éléments véridiques, contradictoires, approximatifs, récents. Il est très sensible à la fraîcheur du contenu. Sur l’exemple de la livraison Deskozo, il reformule un enchaînement de délais et de modalités logistiques contradictoires. Autrement dit : il agrège vite, il restitue vite, et il prend facilement ce qu’on lui donne à manger.
Ce que les sources montrent : vous ne contrôlez pas seul votre vérité de marque
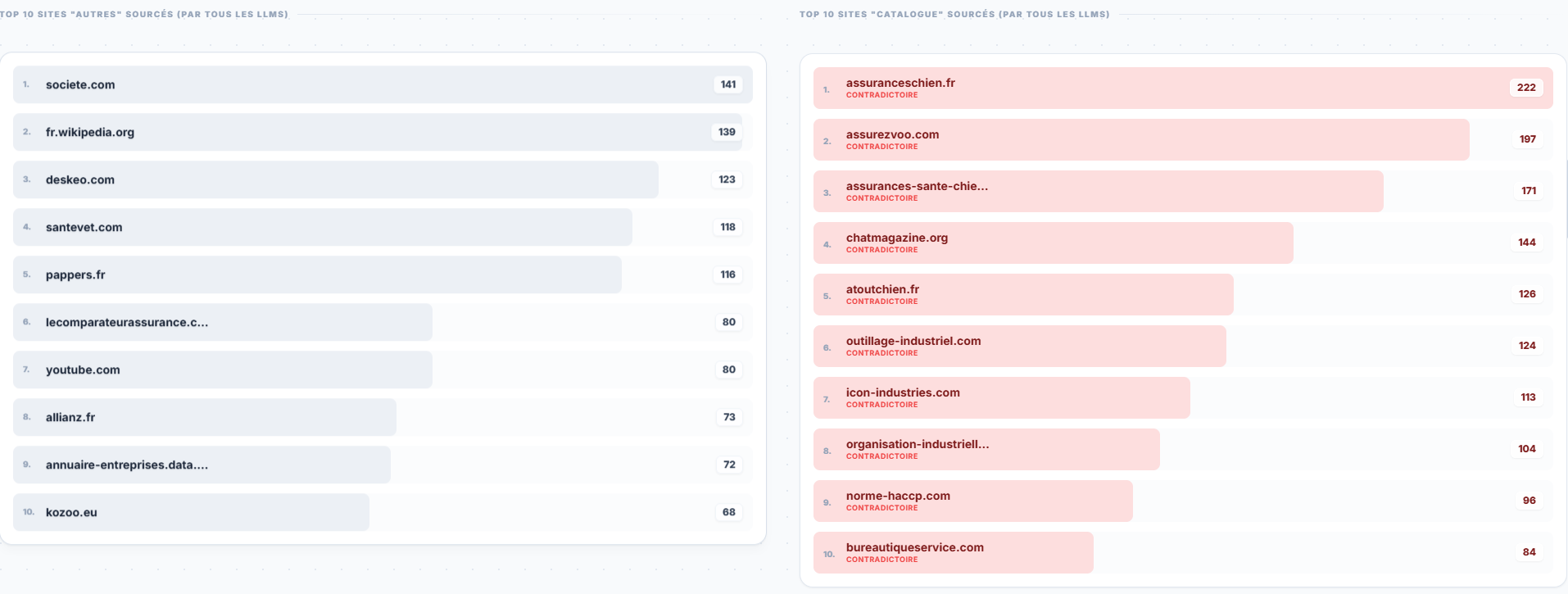
Un autre élément essentiel porte sur les citations et sources.
On y retrouve, côté sources fréquemment utilisées, des sites comme societe.com, fr.wikipedia.org, pappers.fr, YouTube, mais aussi des sites tiers spécialisés ou concurrentiels.
Pour moi, cette image dit quelque chose de simple mais décisif : si vous ne structurez pas suffisamment votre présence, le modèle ira compléter ailleurs.
Et “ailleurs”, ce n’est pas toujours un média de référence. Ce peut être un annuaire, une fiche d’entreprise, un comparateur, un article tiers, un support de niche, un contenu mal interprété, voire une source contradictoire.
Autrement dit, votre marque ne vit pas seule dans le cerveau d’un LLM. Elle vit dans un écosystème de signaux, de citations et de proximités. Si cet écosystème est mal maîtrisé, les modèles viendront le combler eux-mêmes avec ce qu’ils trouvent.
La répartition des réponses
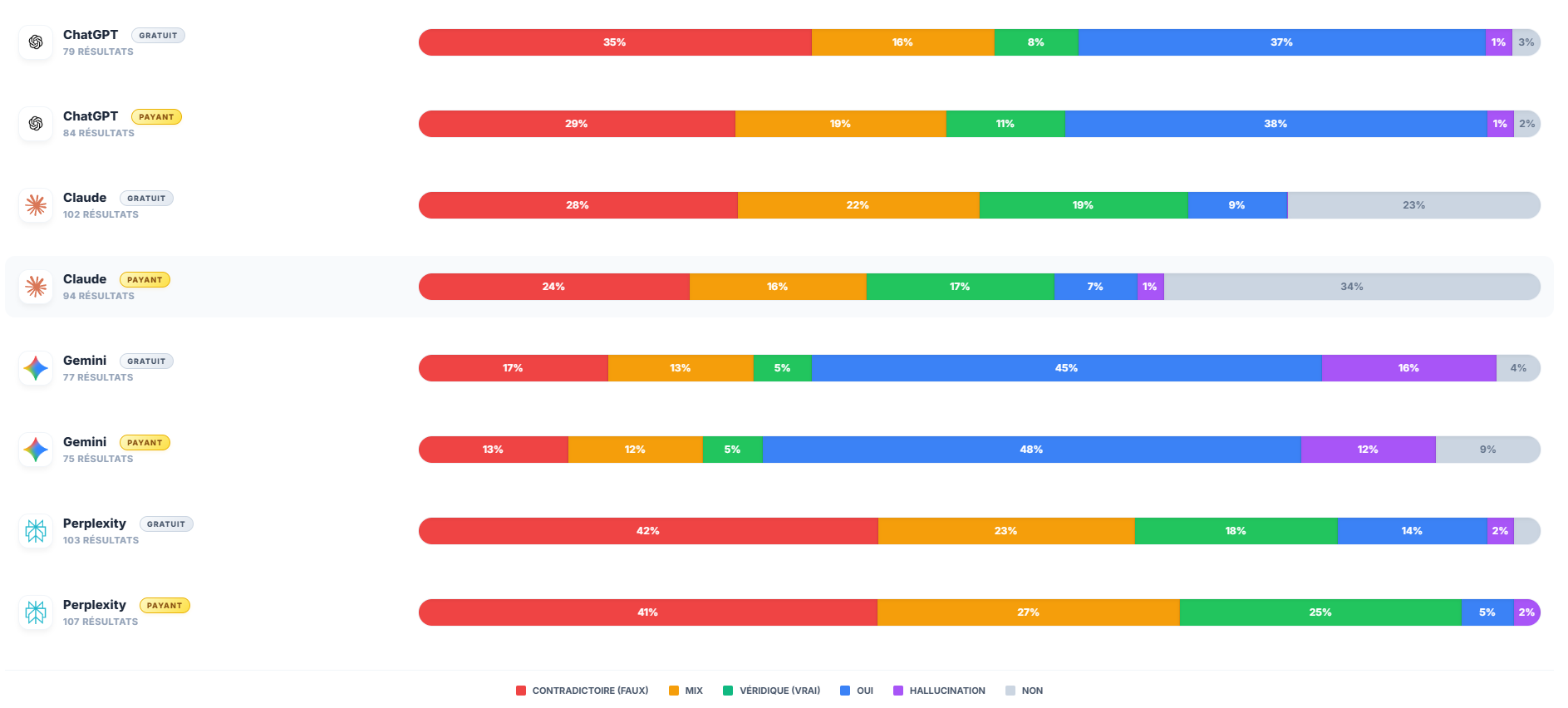
C’est une des parties fondamentales de l’étude parce qu’elle évite un écueil classique : réduire les réponses à “bonnes” ou “mauvaises”.
Dans l’étude, plusieurs catégories coexistent :
- le contradictoire
- le mix
- le véridique
- le oui
- l’hallucination
- et le non
Cette typologie est très utile. Parce qu’en réalité, les réponses des LLM ne sont pas binaires. Une réponse peut être partiellement juste, partiellement fausse, partiellement inventée, ou simplement prudente.
C’est particulièrement important pour le monitoring. Si vous vous contentez de crawler une réponse, d’en extraire le HTML et de la stocker comme un bloc stable, vous ratez une partie du sujet. Une IA conversationnelle n’est pas un SERP statique. Elle peut bifurquer, reformuler, s’auto-corriger, nuancer, ou répondre juste après une première réponse imprécise. Cela pose une vraie question sur la manière de monitorer proprement les environnements GEO.
En Phase 5, la répartition montre par exemple :
- des parts élevées de contradictoire chez Perplexity
- une présence importante du “oui” chez ChatGPT et Gemini
- davantage de prudence chez Claude
- et une part d’hallucination plus visible chez Gemini
Résultat : Ce qu’il faut retenir, ce n’est donc pas “qui gagne”. C’est comment chaque modèle arbitre entre certitude, prudence, confusion et reformulation.
Focus sur un site : le cas deskozo.com

D’abord, il confirme une chose : Claude se montre relativement stable entre ses versions gratuite et payante. Là où d’autres modèles changent davantage de sources ou de comportements. C’est cohérent avec ce qu’on observe dès le début : il prend moins de risques.
Ensuite, Perplexity confirme sa sensibilité à la fraîcheur du contenu. C’est même explicitement mis en avant dans le deck. Cela rejoint ce que l’on constate empiriquement : il varie vite, il prend vite, il recycle vite.
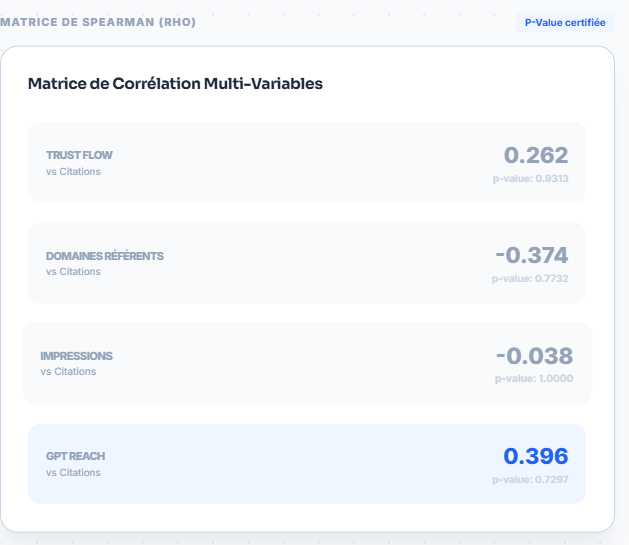
Enfin, le travail de corrélation présenté sur le focus Deskozo, pour ChatGPT, rappelle qu’il n’existe pas un facteur unique. Trust Flow, domaines référents, impressions et GPT Reach interagissent. L’un des enseignements soulignés est que les impressions ressortent comme un signal intéressant à regarder, même s’il serait évidemment trop tôt pour transformer cela en règle générale définitive. La matrice rappelle surtout une idée que l’on partage totalement : sur les LLMs, on reste sur quelque chose de multifactoriel.
Le mini ensemencement : quand 10 contenus suffisent à faire bouger les réponses
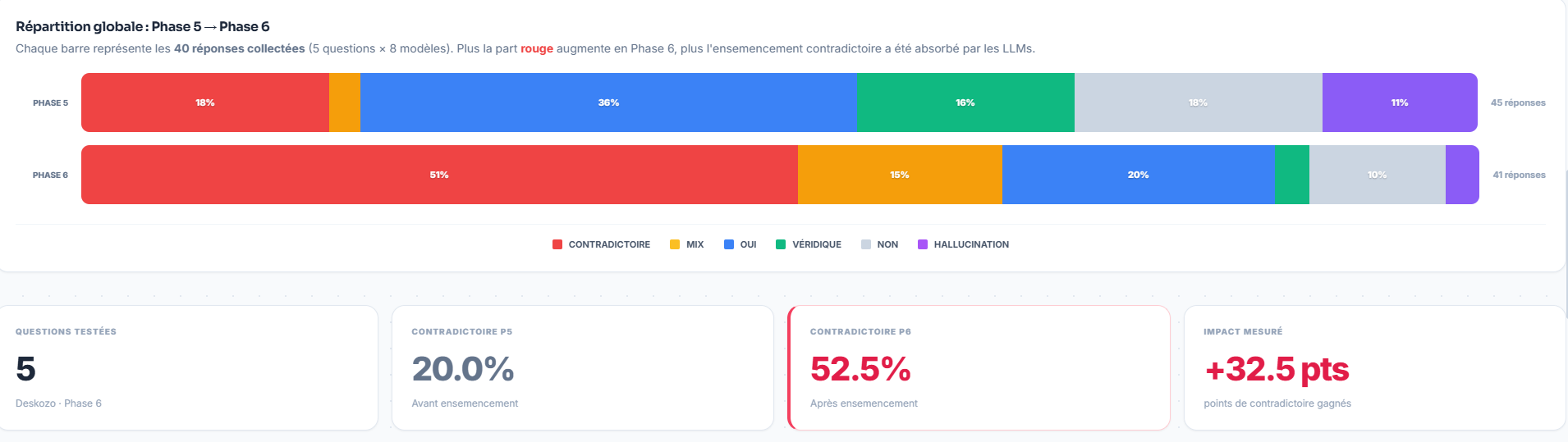
C’est probablement la partie la plus “spectaculaire” du test.
Sur un panel réduit de 5 questions de monitoring autour d’un seul site marque [Deskozo], nous avons volontairement sélectionné des réponses majoritairement positives. Nous avons publié 10 articles contradictoires le 12 mars 2026, puis observé leur indexation le 16 mars 2026. Entre la phase 5 et la phase 6, on passe de 8 à 21 réponses contradictoires, et de 20 % à 52,5 % de contradictoire, soit +32,5 points.
Dit autrement : avec un volume limité, sur un périmètre court, l’environnement contradictoire a réussi à faire fortement bouger la sortie des modèles.
L’analyse détaillée par moteur va dans le même sens :
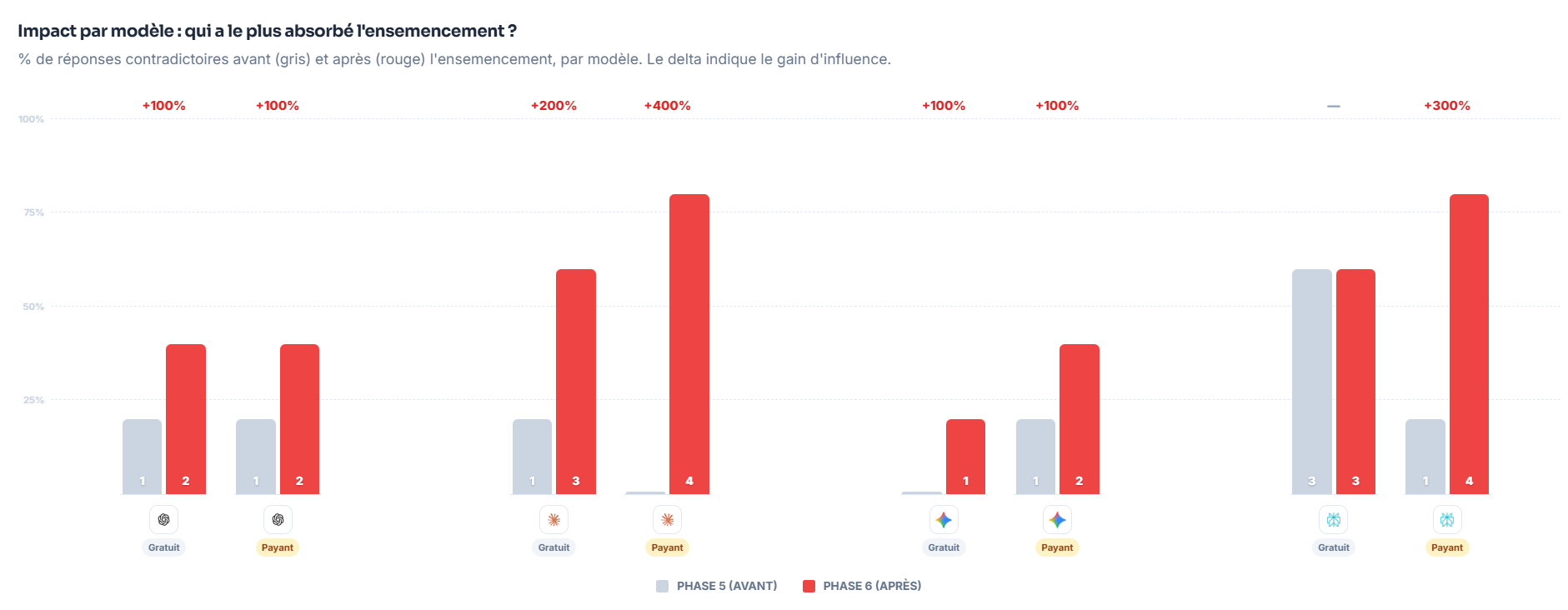
- Les versions gratuite et payante de ChatGPT passent de 1 à 2 réponses contradictoires
- Claude gratuit de 1 à 3
- Claude payant monte de 0 à 4
- Gemini gratuit passe de 0 à 1
- Gemini payant passe de 1 à 2
- Perplexity payant de 1 à 4
Cette séquence très éclairante, non pas parce qu’elle prouve qu’un modèle est “facile à manipuler” de manière générale, mais parce qu’elle montre qu’un petit ensemble de contenus bien placés peut suffire à changer le récit généré.
Pour une marque, c’est à la fois une opportunité et une alerte.
Les grands enseignements de cette étude
La première conclusion, c’est que oui, on peut orienter les IA conversationnelles. Le deck le dit clairement : cette capacité d’orientation dépend notamment de la puissance et de l’antériorité du site.
La deuxième, c’est que tous les modèles ne réagissent pas de la même manière :
- Perplexity est très sensible à la nouveauté et à la fraîcheur des contenus ;
- Claude est plus constant, plus prudent, moins aventureux ;
- Gemini hallucine davantage et s’appuie plus fortement sur son écosystème avec une certaine solidité dans ses réponses ;
- ChatGPT veut presque toujours répondre, même lorsqu’il a tort, tout en restant dans cette étude celui qui ressort comme le plus fiable globalement.
La troisième, et peut-être la plus importante, est que la question n’est pas “comment manipuler un LLM ?”. La vraie question, côté marque, est plutôt : comment faire en sorte que votre vérité de marque soit la plus présente, la plus cohérente et la plus facile à reprendre ?
Parce que dans la vraie vie, l’objectif n’est évidemment pas de diffuser du contradictoire. L’objectif, c’est l’inverse : agir comme un écosystème éditorial, RP et de notoriété, capable de faire émerger les bons signaux au bon endroit, pour que les modèles vous comprennent mieux et vous reprennent mieux.
Et maintenant ?
Cette étude n’est qu’une première brique. Le deck prévoit déjà une suite entre mai et septembre, avec notamment plusieurs axes :
- suivre l’évolution des données dans le temps
- publier des articles informatifs VÉRIDIQUES en masse
- publier sur des sites anglophones… etc.
C’est à mon sens la suite logique. Parce qu’une fois qu’on a observé ce qui se passe sur des requêtes de marque, la vraie marche suivante consiste à voir si une marque peut émerger aussi sur des requêtes génériques.
Et c’est là que le sujet devient encore plus stratégique.




